Basic Data Pipelines with  and
and  [and
[and  ]
]
From Zero to ETL with Minimal Fuss
Gordon Inggs, Data Scientist, in his private capacity
Talk Outline¶
- Why do this to yourself?
- What do we get from using Airflow, Docker and Kubernetes?
- How to do this right now?
- Reflection:
- Why is this a bad idea?
- How to do this better?
1. Why do you want a data engineer pipeline?¶

- Automation
- Modularity
(awkward shoehorn) Control vs Data flow¶
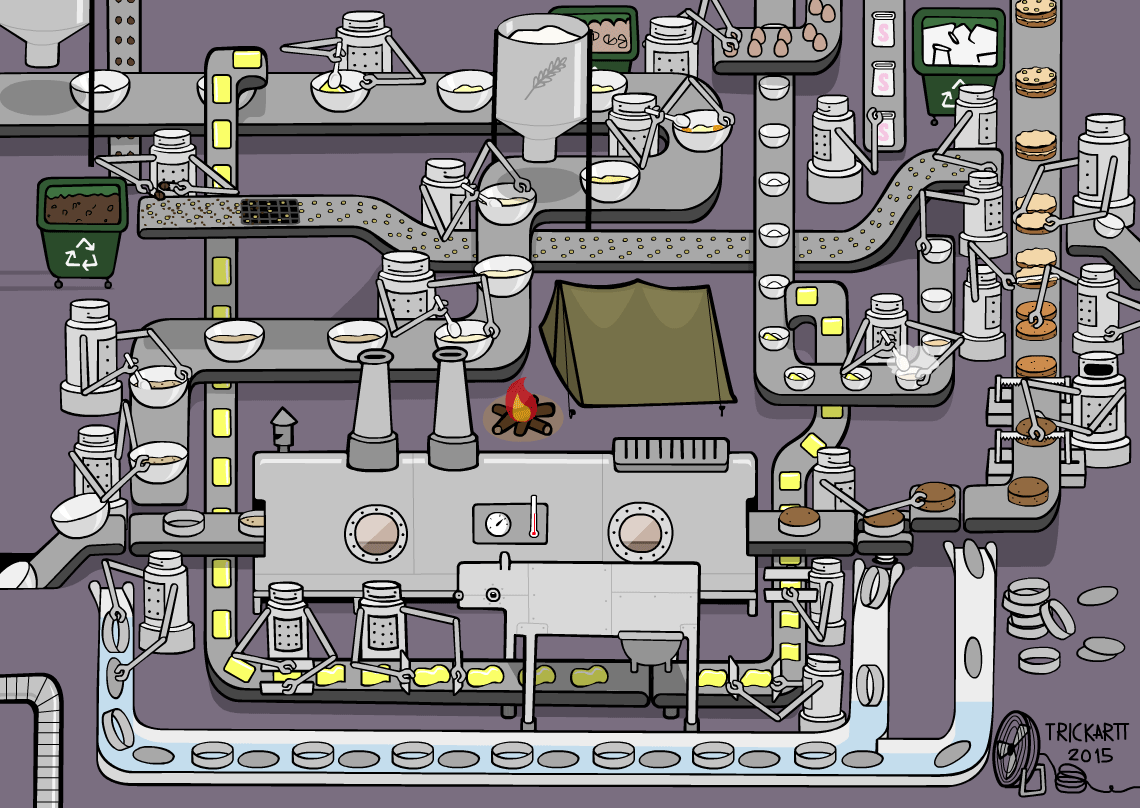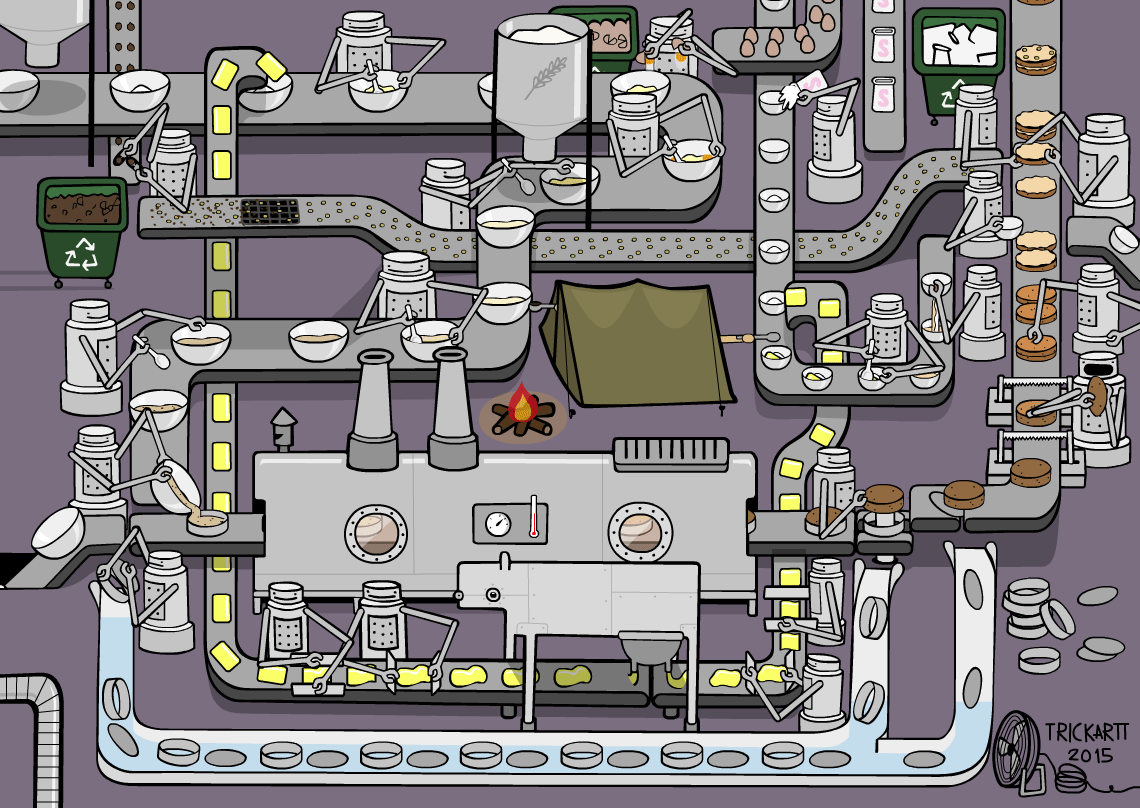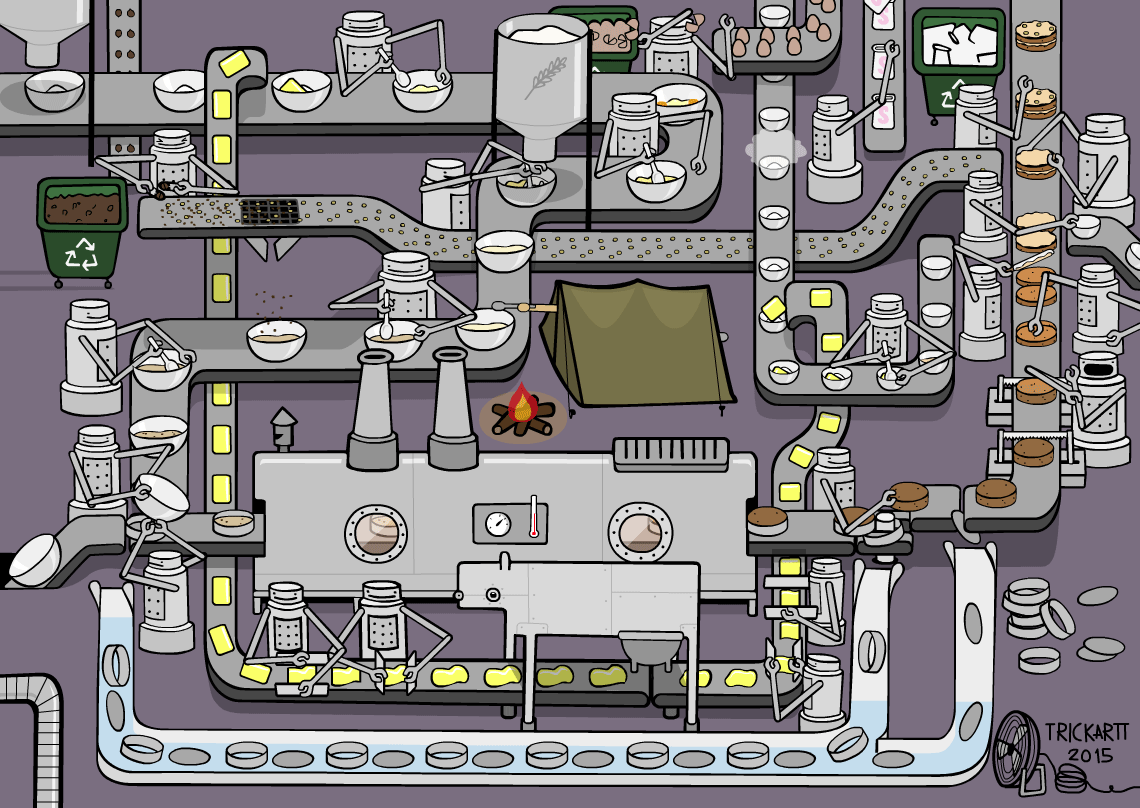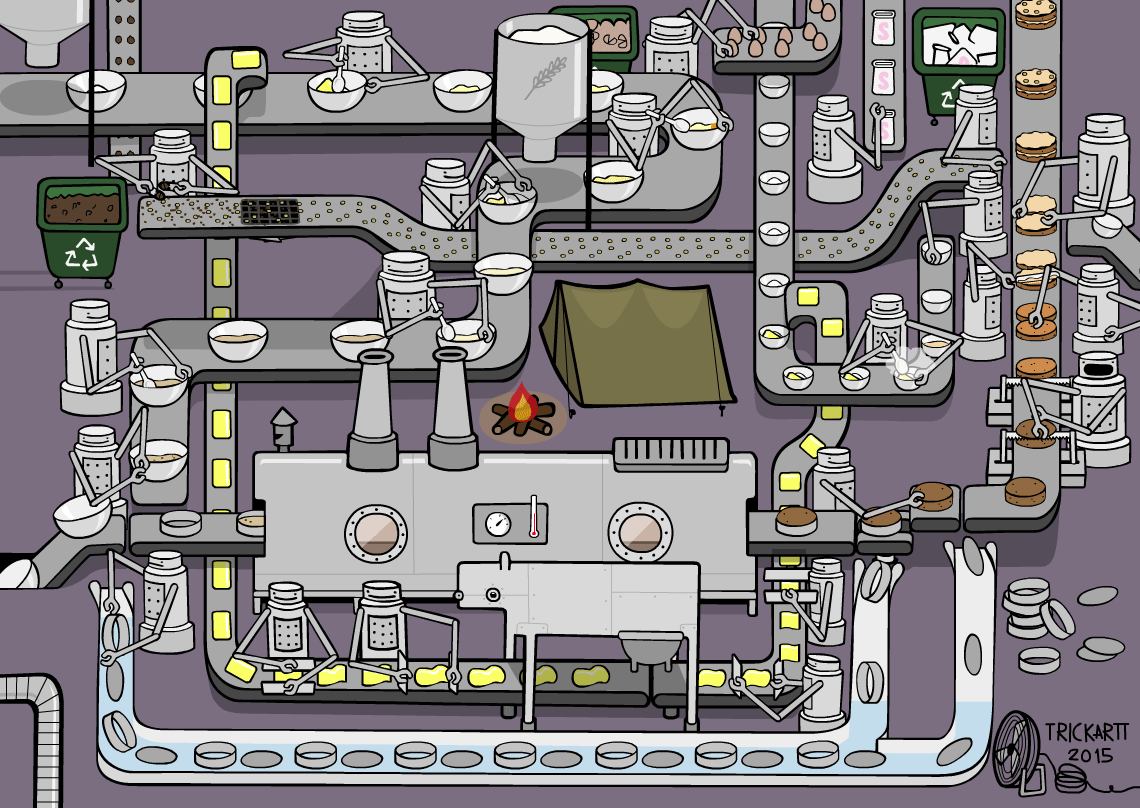
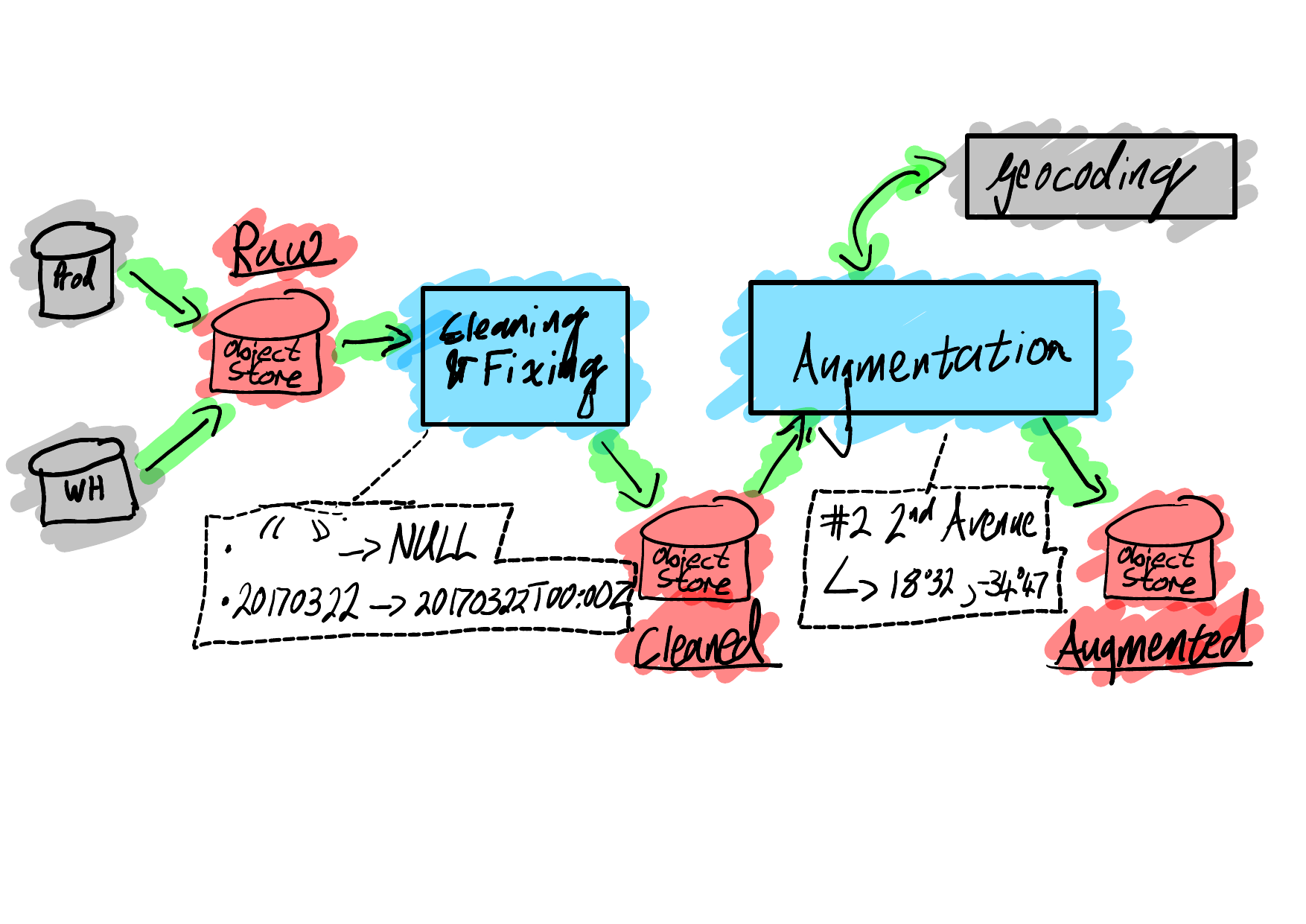
Our Experience¶
- Airflow + Docker - 0 to ~5 data pipelines.
- Airflow + Docker + Kubernetes - scaling past 5
2.1 Why do you want to use Airflow?¶

What is Airflow?¶
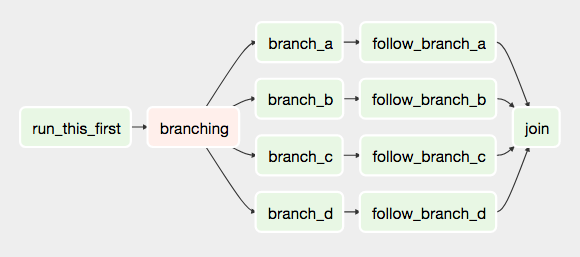
Visibility¶

Visibility (again)¶

Visibility (yet again)¶
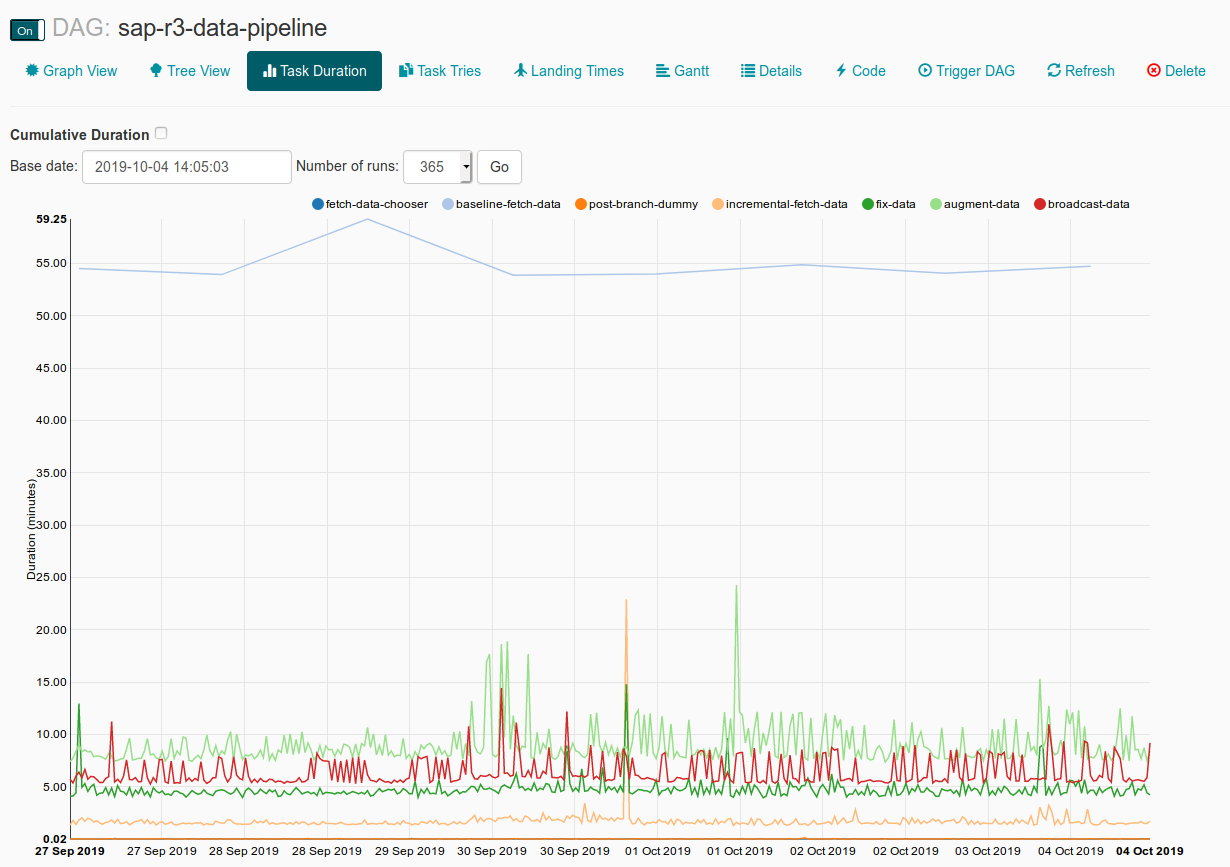
Expressiveness¶
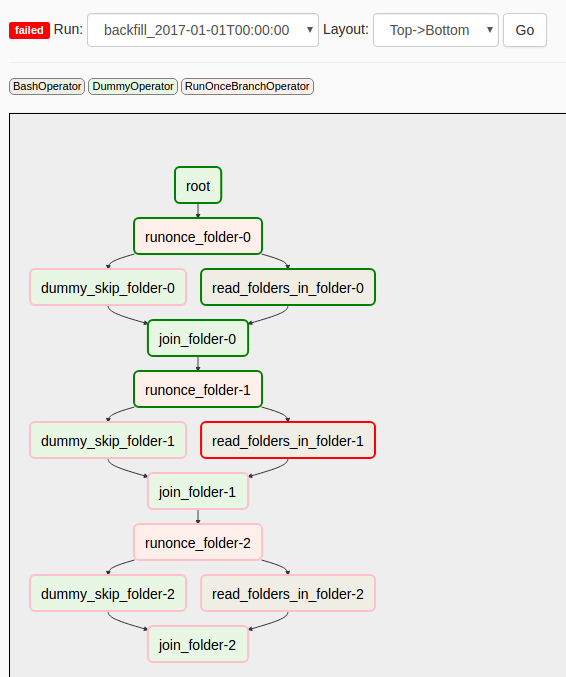
2.2 Why do you want to use Docker (with Airflow)?¶

Dependency Closure¶
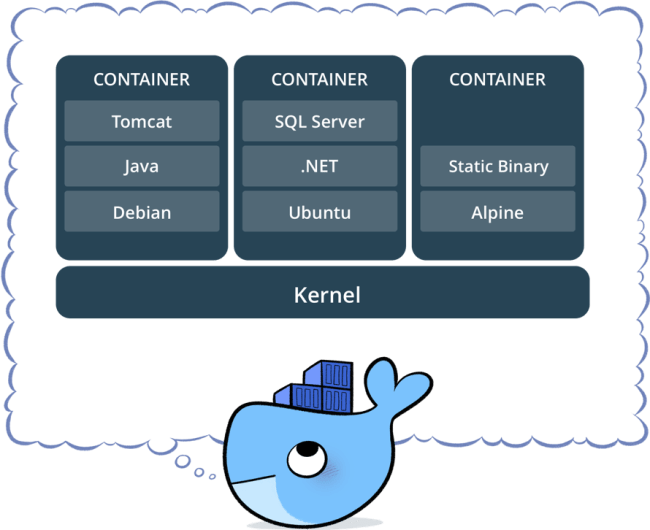
Resource-efficient Isolation¶
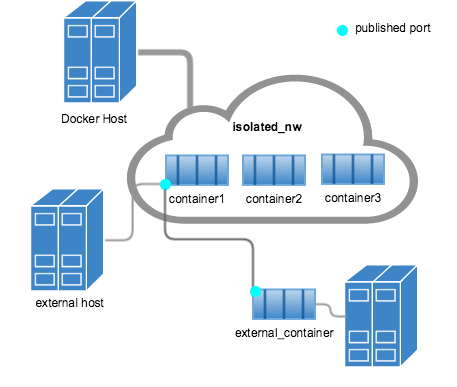
2.3 And Kubernetes!?!¶

One (sort-of) word: Scaling¶
3. How to do this Right Now¶

What you need:¶
Using your ahem bare metal, FOSS Data Science Env.
- Airflow Checklist:
LocalExecutor.- Separate DB for Airflow state - PostgreSQL, MySQL, etc.
- Docker/Kubernetes Python SDK
- Docker: Read/write access to Docker socket (
/var/run/docker.sock) - k8s: Read/write access to k8s API

Docker Checklist:
- Docker images with dependencies
Scripts to run tasks inside images:
#!/usr/bin/env bash PYTHONPATH="$PIPELINE_DIR" python3 "$PIPELINE_DIR"/my_module/my_task.py
In [ ]:
def pipeline_docker_task(task_name):
"""Function inside Airflow DAG"""
docker_name = f"{PIPELINE_PREFIX}-{task_name}-{str(uuid.uuid4())}"
docker_command = f"bash -c '/run_{task_name}.sh'"
operation_run = docker_client.containers.run(
name=docker_name,
command=docker_command,
**docker_run_args
)
return operation_run.decode("utf-8")
# Node in dag
pipeline_operator = PythonOperator(
task_id=TASK_ID,
python_callable=pipeline_docker_task,
op_args=[TASK_NAME],
dag=dag,
)
Kubernetes Checklist:
- Docker images with dependencies
Scripts to run tasks inside images:
#!/usr/bin/env bash PYTHONPATH="$PIPELINE_DIR" python3 "$PIPELINE_DIR"/my_module/my_task.py
In [ ]:
def pipeline_k8s_operator(task_name, kwargs):
"""Factory for k8sPodOperator"""
name = f"{PIPELINE_PREFIX}-{task_name}"
run_args = {**k8s_run_args.copy(), **kwargs}
run_cmd = f"bash -c '/run_{task_name}.sh'"
operator = KubernetesPodOperator(
cmds=["bash", "-cx"],
arguments=[run_cmd],
name=name, task_id=name,
dag=dag,
**run_args
)
return operator
pipeline_operator = pipeline_k8s_operator(
TASK_NAME,
K8S_KWARGS
)
4. Why is this a Bad Idea?¶

Problems we've run into (so far)¶
- Loading DAGs into Airflow
- Scaling beyond one docker host
- Weird Docker performance problems:
- Noisy neighbours
- Heavy load on Docker daemon
- containerisation $\neq$ virtualisation

5. How to do this better?¶

Improving¶
Bar to beat: 6 months to a year, no dedicated administration
- Serverless containers (e.g. AWS Fargate)
- Kubernetes (scaling) - this is the route we took. #NoRegrets
Different Paradigm¶
Warning: Speculative
- $\mu$Service Architecture - even more modular
- Declarative/reconciliation approach
